

Перевод
Ссылка на автора

- ВВЕДЕНИЕ ПИСИФТА
- Начало работы — Настройка библиотеки
- Что такое частный и безопасный ИИ?
- Введение в федеративное обучение и сохранение конфиденциальности
- Что такое федеративное обучение (FL)?
- ОСНОВЫ
- Краткое введение в федеративное обучение
- Необходимость защиты конфиденциальности
- Будущее машинного обучения — это сотрудничество
- Федеративное обучение под капотом
- Обзор компонентов федеративного обучения
- Будущие направления
- Использованная литература
- УСТАНОВКА
- Создание данных альянсов
- Новая бизнес-модель?
- ДОБАВЛЕНИЕ СЕКРЕТНОГО ОБМЕНА
- How Federated Learning Could Transform Healthcare
- КАК ЭТО ОТЛИЧАЕТСЯ ОТ ДЕЦЕНТРАЛИЗОВАННЫХ ВЫЧИСЛЕНИЙ?
- PySyft
- Подготовка данных и отправка их удаленным работникам
- How Federated Learning Works
- ГОМОМОРФНОЕ ШИФРОВАНИЕ
- ССЫЛКИ
- Обнаружение SMS-спама с помощью PySyft и PyTorch
- Вертикальное и горизонтальное федеративное обучение
- Built by Healthcare for Healthcare
- Обучение модели ГРУ
- Вывод
- СТРАТЕГИЯ
ВВЕДЕНИЕ ПИСИФТА
Мы будем использовать PySyft для реализации федеративной модели обучения. PySyft — это библиотека Python для безопасного и частного глубокого обучения.

Федеративное обучение — это не только перспективная технология, но и новая бизнес-модель ИИ.Действительно, как консультант, мне недавно было поручено дать рекомендации о том, как медицинская компания может создать «альянс данных» с некоторыми конкурентами, создав систему федеративного обучения.Цель этой статьи — объяснить вам, как FL может породить новую экосистему данных и создать альянсы данных.
Начало работы — Настройка библиотеки
Чтобы установить PySyft, рекомендуется сначала настроить среду conda:
conda create -n pysyft python=3conda activate pysyft # or source activate pysyftconda install jupyter notebook
Затем вы устанавливаете пакет:
pip install syft
Пожалуйста, убедитесь, что в вашей среде установлен PyTorch 1.0.1 или выше.
Если у вас есть ошибка установки относительно zstd, попробуйте удалить zstd и переустановить его.
pip uninstall zstdpip install —upgrade zstd
Если вы все еще получаете ошибки при настройке, вы можете использовать Colab Записать и запустить следующую строку кода:
!pip install syft
Что такое частный и безопасный ИИ?
Эта новая область состоит из множества методов, которые позволяют инженерам ML обучать модели, не имея прямого доступа к данным, используемым для обучения, и избегать их получения какой-либо информации о данных с помощью криптографии.
Кажется, черная магия не так ли?
Эта структура опирается на три основных метода:
- Федеративное обучение
- Дифференциальная конфиденциальность
- Безопасные многопартийные вычисления
В этой статье я расскажу об Федеративном обучении и его приложении для обнаружения SMS-спама.
The key to becoming a medical specialist, in any discipline, is experience.
Knowing how to interpret symptoms, which move to make next in critical situations, and which treatment to provide — it all comes down to the training you’ve had and the opportunities you’ve had to apply it.
For AI algorithms, experience comes in the form of large, varied, high-quality datasets. But such datasets have traditionally proved hard to come by, especially in the area of healthcare.
Medical institutions have had to rely on their own data sources, which can be biased by, for example, patient demographics, the instruments used or clinical specializations. Or they’ve needed to pool data from other institutions to gather all of the information they need.
Federated learning makes it possible for AI algorithms to gain experience from a vast range of data located at different sites.
В последние годы мы все стали свидетелями важного и быстрого развития в области искусственного интеллекта и машинного обучения. Это быстрое развитие происходит благодаря повышению вычислительной мощности (доступной для последних поколений графических процессоров и процессоров TPU) и огромному количеству данных, которые накапливались годами и создаются каждую секунду.
От разговорных помощников до выявления рака легких мы можем ясно видеть несколько применений и различные преимущества разработки ИИ для нашего общества. Однако в последние годы этот прогресс сопровождался ценой: в какой-то степени потеря конфиденциальности. Кембридж Аналитика Скандал Это событие вызвало тревогу по поводу конфиденциальности и конфиденциальности данных. Кроме того, растущее использование данных техническими компаниями, маленькими или большими, побудило власти нескольких юрисдикций работать над регулированием и законами, касающимися защиты данных и конфиденциальности. GDPR В Европе самый известный пример таких действий.
Эти проблемы и правила не имеют прямой совместимости с разработкой ИИ и машинного обучения, поскольку модели и алгоритмы всегда основывались на доступности данных и возможности централизовать их на больших серверах. Для решения этой проблемы интерес исследователей и практиков ОД привлекает новое направление исследований: частный и безопасный ИИ.
Введение в федеративное обучение и сохранение конфиденциальности
Федеративное обучение включает в себя обучение на большом корпусе высококачественных децентрализованных данных, представленных на нескольких клиентских устройствах. Модель обучается на клиентских устройствах и, следовательно, нет необходимости загружать данные пользователя. Хранение личных данных на клиентском устройстве позволяет им напрямую и физически контролировать свои собственные данные.

Рисунок 1: Федеративное обучение
Сервер обучает исходную модель предварительно доступным данным прокси. Первоначальная модель отправляется выбранному числу подходящих клиентских устройств. Критерий соответствия гарантирует, что пользовательский опыт не будет испорчен при попытке обучить модель. Оптимальное количество клиентских устройств выбирается для участия в процессе обучения. После обработки пользовательских данных обновления модели передаются на сервер. Сервер объединяет эти градиенты и улучшает глобальную модель.
Все обновления моделиобрабатывается в памятиа такжесохраняться в течение очень короткого периодавремени на сервере. Затем сервер отправляет улучшенную модель обратно на клиентские устройства, участвующие в следующем раунде обучения. После достижения желаемого уровня точности модели на устройстве можно настроить для персонализации пользователя. Затем они больше не имеют права участвовать в тренинге. На протяжении всего процесса данные не покидают клиентское устройство.
Что такое федеративное обучение (FL)?
Не вдаваясь в технические детали, FL можно определить как распределенную систему машинного обучения, которая позволяет создавать коллективную модель из данных, которые распределены по владельцам данных.
Данные, необходимые для проектов AI, включают в себя несколько элементов. Я бы сказал, что наша способность создавать великолепные проекты ИИ всегда ограничена. Доступ к внешним данным очень ограничен и представляет собой реальную проблему при создании современных приложений ИИ. Хуже всего то, что из-за конкуренции в отрасли, обеспечения конфиденциальности и других административных процедур даже интеграция данных между различными отделами одной и той же компании представляет собой проблему.
В общем, централизованная ОД далеко не идеальна. Действительно, обучение моделям требует от компаний накапливать горы соответствующих данных для центральных серверов или центров обработки данных. В некоторых проектах это означает сбор конфиденциальных данных пользователя.

Как следствие, централизованное машинное обучение часто недоступно для большинства предприятий. Само собой разумеется, что «простая» задача сбора всех данных, необходимых для проекта, довольно дорогая и отнимает много времени.
Я часто сталкиваюсь с двумя проблемами, работая над проектом ML:
В зависимости от проекта владелец нужных вам данных может просто не захотеть делиться ими с вашей компанией. Это тот случай, когда речь идет о конфиденциально защищенных данных или медицинских данных, защищенных законом.
Во-вторых, значительное количество ценных обучающих данных создается на оборудовании на границе медленных и ненадежных сетей, таких как смартфоны или оборудование на промышленных объектах.Я понял, что общение с такими устройствами может быть медленным и дорогим для компании.
Федеративное обучение дает ответ на большинство вопросов, связанных с традиционным машинным обучением. Действительно, алгоритм обучения перемещается на край сети, поэтому данные никогда не покидают устройство, будь то мобильный телефон или серверы отделения больницы. Как только модель изучает данные, результаты загружаются и объединяются с обновлениями со всех других устройств в сети.Затем улучшенная модель предоставляется всей сети.
ОСНОВЫ
Давайте начнем с импорта библиотек и инициализации хука.
Это сделано для того, чтобы переопределить методы PyTorch для выполнения команд на одном работнике, которые вызываются на тензорах, управляемых локальным работником. Это также позволяет нам перемещать тензоры между рабочими. Работники объясняются ниже.
Виртуальные работники — это сущности, присутствующие на нашей локальной машине. Они используются для моделирования поведения реальных работников.
Для работы с работниками, распределенными в сети, PySyft предлагает два типа работников:
- Работники сетевых сокетов
- Работники веб-сокетов
Рабочие веб-сокетов могут быть созданы из браузера с каждым рабочим на отдельной вкладке.
Здесь Джейк — наш виртуальный работник, который можно рассматривать как отдельную сущность на устройстве. Давайте отправим ему некоторые данные.
Когда мы отправляем тензор Джейку, нам возвращается указатель на этот тензор. Все операции будут выполнены с этим указателем. Этот указатель содержит информацию о данных, присутствующих на другом компьютере. В настоящее время,Иксявляется PointTensor.
Использоватьполучить()способ вернуть значениеИксс устройства Джейка. Однако при этом тензор на устройстве Джейка стирается.
Когда мы отправляем PointTensorИкс(указывая на тензор на машине Джейка) другому работнику — Джону, вся цепочка отправляется Джону, и возвращается PointTensor, указывающий на узел на устройстве Джона. Тензор все еще присутствует на устройстве Джейка.

clear_objects ()Метод удаляет все объекты из рабочего.
Предположим, что мы хотим переместить тензор с машины Джейка на машину Джона Мы могли бы сделать это, используяОтправить()метод, чтобы отправить «указатель на тензор» Джону и позволить ему вызватьполучить()метод. PySfyt предоставляетremote_get ()способ сделать это. Есть также удобный метод -переехать(), чтобы выполнить операцию.

Краткое введение в федеративное обучение

Необходимость защиты конфиденциальности
Проще говоря, вместо отправки ваших данных третьей стороне, Федеративное обучение переносит модель в ваши данные, при этом шифруя каждый шаг.
Будущее машинного обучения — это сотрудничество
Конфиденциальность — не единственная проблема, для решения которой используется Федеративное обучение; это также устраняет препятствия, которые в настоящее время мешают нам строить модели с большей точностью. Одна из таких проблем заключается в том, что нет центрального источника для получения всех данных, необходимых для обучения этих моделей. Для обучения модели, которая рисует всю картину, потребуется ряд типов данных, которые часто распределены между учреждениями. Например, чтобы охватить финансовое положение человека и дать представление о нем, модель должна быть обучена на данных, полученных из нескольких банков и кредитных служб, поведении розничной торговли в Интернете и платежных привычках. Кроме того, при передаче данных между отделами одной компании могут возникнуть административные проблемы или проблемы, связанные с конфиденциальностью.
Федеративное обучение предоставляет возможность различным сторонам, каждая из которых владеет разными частями головоломки, совместно обучать модели, которые являются более точными, чем модели, обученные на отдельных источниках данных.
Федеративное обучение под капотом
Федеративное обучение на высоком уровне можно описать в три этапа:
- Общая глобальная модель машинного обучения обучается на доступных данных и развертывается на децентрализованной платформе.
- Модель загружается на пограничное устройство, которым может быть смартфон, ноутбук или другое интеллектуальное устройство, которое затем обновляет модель, используя данные, которые она содержит.
- Обновления, такие как вычисленные градиенты, зашифровываются и отправляются обратно на сервер, где обновления с нескольких устройств усредняются и используются для улучшения основной общей модели.
- Затем общая модель загружается на периферийные устройства, что приносит пользу разработчикам данных и кураторам модели.
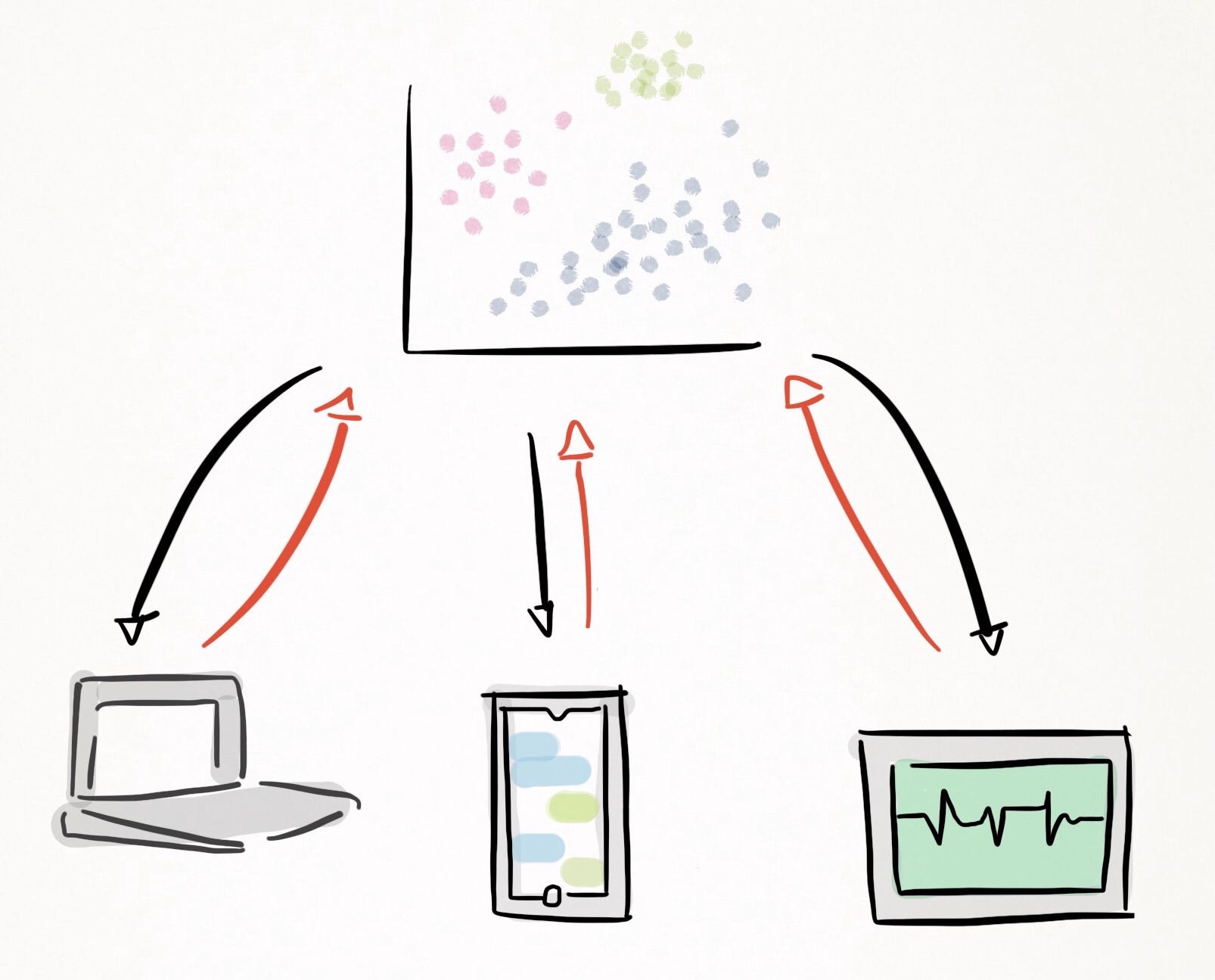
Обзор компонентов федеративного обучения
Я создал диаграмму, чтобы проиллюстрировать различные элементы, составляющие федеративное обучение на очень высоком уровне:

Основы федеративного обучения составляют три момента: конфиденциальность, структура данных и тип модели. Эти точки далее разветвляются с новыми исследованиями, постоянно меняющими ландшафт, повышая сложность и добавляя глубины.
- Конфиденциальность. Конфиденциальность — важнейший аспект федеративного обучения. Независимо от того, являются ли авторы данных корпорациями или частными лицами, сохранение конфиденциальности способствует доверию в сотрудничестве, защищает конфиденциальные данные и обеспечивает законные права отдельных лиц. В этой статье не будут подробно останавливаться на этих темах. и поэтому я связал статью, в которой подробно рассматривается каждый из них. Differential Privacy Гомоморфное шифрование Криптография GAN
- Структура данных. Федеративное обучение подразделяется на категории в зависимости от структуры данных, на которых обучается модель. Существует три типа категорий структур данных: горизонтальное федеративное обучение, вертикальное федеративное обучение и трансферное обучение (подробнее об этом в будущей статье). Эти структуры описывают, как организованы данные, в частности, используют ли наборы данных одно и то же пространство функций или они используют одни и те же образцы. Эти два описания относятся к горизонтальному и вертикальному обучению соответственно.
- Тип модели. Укажите, является ли обучаемая модель нейронной сетью или моделью статистического обучения. Это будет зависеть от типа данных, количества данных и желаемого результата прогноза.
Будущие направления
Хотя федеративное обучение может стать решением проблем, связанных с большими объемами данных на нескольких устройствах, некоторые препятствия все еще существуют.
- Узкие места в ресурсах. Эти проблемы включают ситуации, когда у подключенных устройств Интернета вещей различается время автономной работы во время тренировочного раунда, что может привести к отключению некоторых из них. Различия в коммуникации, такие как способность устройств подключаться к сети Wi-Fi, 3G или 4G, будут влиять на сеть. Наконец, технические характеристики оборудования, такие как память и ЦП, могут различаться для разных устройств в сети.
- Разница в данных — данные на каждом устройстве будут отличаться по качеству, количеству и согласованности. Например, при сборе данных изображения для распознавания лиц освещение на изображениях, разнообразие лиц и объем внесенных данных повлияют на локально обученную модель. Эти локальные модели будут сильно различаться по качеству и в конечном итоге повлияют на общее качество и точность глобальной модели.
Использованная литература
PySyft предоставляетдоля()Способ разделения данных на аддитивные секретные акции и отправки их указанным работникам. Для работы с десятичными числами,fix_precision ()Метод используется для представления десятичных чисел в виде целочисленных значений под капотом.
доля()Метод используется для распределения акций между несколькими работниками. Каждый указанный работник получает долю и не имеет представления о фактической стоимости.
Как вы видете,Икстеперь указывает на три акции, присутствующие на машине Джейка, Джона и Secure_worker соответственно.

Рисунок 6: Шифрование x на три части.

Рисунок 7: Распределение долей x среди 3 VirtualWorkers.

Рисунок 8: Шифрование y в 3 акции.

Рисунок 9: Распределение долей y среди 3 VirtualWorkers.
Обратите внимание, что значениеZполучается после добавленияИкса такжеYхранится в машинах трех рабочих.Zтакже зашифрован.

Рисунок 10: Выполнение вычислений на зашифрованных входах.

Рисунок 11: Расшифровка результата, полученного после вычисления на зашифрованных входах.
Значение, полученное после выполнения добавления для зашифрованных акций, равно значению, полученному путем сложения фактических чисел.
УСТАНОВКА
Обучение модели на клиентском устройстве защищало конфиденциальность пользователя. Но как насчет конфиденциальности модели? Загрузка модели может угрожать интеллектуальной собственности организации!
Безопасные многопартийные вычисления, которые состоят из секретного аддитивного обмена, дают нам возможность проводить обучение модели без раскрытия модели.
Чтобы защитить вес модели, мы тайно делимся моделью между клиентскими устройствами.
Как показано в разделе SECRET SHARING с использованием PYSYFT, теперь модель, входные данные, выходные данные модели, веса и т. Д. Также будут зашифрованы. Работа на зашифрованных входах даст зашифрованный вывод.
Пожалуй, самое простое для понимания понятие частного ИИ, Федеративное обучение — это метод обучения моделей ИИ без необходимости переноса данных на центральный сервер. Термин был впервые использован Google в бумага опубликовано в 2016 году.

Схема федеративного учебного задания
Основная идея состоит в том, что вместо того, чтобы переносить данные в модель, мы отправляем модель туда, где эти данные находятся.
Поскольку данные расположены на нескольких устройствах (которые я буду называть рабочими отсюда), модель отправляется каждому рабочему, а затем отправляется обратно на центральный сервер.
Один простой пример федеративного обучения в реальном мире происходит с устройствами Apple. Приложение QuickType (инструмент прогнозирования текста Apple) фактически использует модели, которые время от времени отправляются на устройства iOS через WiFi, обучаются локально с использованием данных пользователей и отправляются обратно на центральный сервер Apple с обновленными весами.
Создание данных альянсов
Я считаю, что эта новая бизнес-модель, основанная на федеративном обучении, должна поддерживаться промышленным альянсом данных, иначе она обречена на провал. Альянс может состоять из нескольких объектов. Присоединяясь к альянсу, субъекты могут сотрудничать с использованием данных в рамках федеративного обучения.

Альянс данных, над которым я работаю, будет выглядеть так:Это будет многопартийная система, состоящая издве или более организаций формируют альянс для обучения общей модели на своих отдельных наборах данных посредством федеративного обучения. Отобранные компании и организации будут поощряться к вступлению в альянс, и этот же альянс будет иметь четкий механизм стимулирования.
Я считаю, что для полной коммерциализации федеративного обучения среди различных организаций необходимо разработать справедливую платформу и механизмы стимулирования.
Члены альянса пользуются правами и интересами, а также выполняют обязанности. По моему мнению, альянс должен использовать блокчейн для достижения консенсуса между всеми сторонами, регистрации вклада каждой из сторон в постоянный механизм регистрации данных и награждения сторон, которые вносят выдающийся вклад.
Сохранение конфиденциальности данных является основным преимуществом федеративного обучения здесь для каждого участвующего субъекта для достижения общей цели.
Я бы порекомендовал полагаться на нейтральную третью сторону, которая могла бы отвечать за предоставление инфраструктуры для агрегирования весов моделей и установления доверия между компаниями в альянсе.
Более того, структуры данных и параметры, как правило, похожи, но не обязательно должны быть одинаковыми, но для каждого клиента требуется много предварительной обработки для стандартизации входных данных модели. Нейтральная третья сторона может прекрасно справиться с этой частью проекта.

В настоящее время хранилища данных и акцент на конфиденциальности данных являются важными проблемами для искусственного интеллекта, но федеративное обучение может быть решением.Это может создать единую модель для нескольких предприятий, в то время как локальные и конфиденциальные данные защищены, так что компании могут получить выгоду вместе, не беспокоясь об обмене данными.
Новая бизнес-модель?
Модель облачных вычислений ставится под сомнение, как никогда раньше. Компании больше не могут игнорировать растущую важность конфиденциальности данных и безопасности данных. Более того, связь между прибылью компании и ее данными становится все более очевидной в эпоху ИИ.Однако бизнес-модель федеративного обучения предоставила новую парадигму для приложений, использующих данные.
Цель федеративного обучения заключается в том, что когда изолированный набор данных, используемый каждой компанией, не может создать точную модель, механизм федеративного обучения позволяет компаниям совместно использовать единую модель без прямого обмена данными.Компании смогут получить доступ к большему количеству данных и лучше обучать своих моделей.
Справедливое совместное использование данных может быть достигнуто либо путем создания метамодели из подмоделей, которые создает каждая сторона, так что передаются только параметры модели, либо с использованием методов шифрования, чтобы обеспечить безопасную связь между различными сторонами. Методы блокчейна также могут помочь усилить контроль данных.
Проще говоря, федеративное обучение позволяет различным владельцам данных на уровне организации сотрудничать и делиться своими данными. В недавнем бумага исследователи (Qiang Yang et al.) предполагают различные конфигурации, в которых это может происходить.
ДОБАВЛЕНИЕ СЕКРЕТНОГО ОБМЕНА
В секретном обмене мы разделили секретИксна множественное количество акций и распределить их среди группы секретных владельцев. СекретИксможет быть построен только тогда, когда все акции, на которые он был разделен, доступны.
Например, скажем, мы разделилиИксна 3 акции:x1,x2,а такжеx3, Мы случайным образом инициализируем первые две акции и рассчитываем третью акцию какx3знак равноИкс- (x1+x2). Затем мы распределяем эти акции среди 3 тайных владельцев. Секрет остается скрытым, поскольку каждый человек держит только одну акцию и не имеет представления об общей стоимости.
Мы можем сделать его более безопасным, выбрав диапазон стоимости акций. ПозволятьQ, большое простое число, быть верхним пределом. Теперь третья доля,x3равноQ -(x1+x2)% Q+Икс,

Рисунок 4: Шифрование x в трех долях.
Процесс дешифрования будет делиться суммируемым модулемQ,

Рисунок 5: Расшифровка x из трех акций.
How Federated Learning Could Transform Healthcare
Federated learning could revolutionize how AI models are trained, with the benefits also filtering out into the wider healthcare ecosystem.
Larger hospital networks would be able to work better together and benefit from access to secure, cross-institutional data. While smaller community and rural hospitals would enjoy access to expert-level AI algorithms.
It could bring AI to the point of care, enabling large volumes of diverse data from across different organizations to be included in model development, while complying with local governance of the clinical data.
Clinicians would have access to more robust AI algorithms, based on data that represents a wider demographic of patients for a particular clinical area or from rare cases that they would not have come across locally. They’d also be able to contribute back to the continued training of these algorithms whenever they disagreed with the outputs.
Healthcare startups could bring cutting-edge innovations to market faster, thanks to a secure approach to learning from more diverse algorithms.
Meanwhile, research institutions would be able to direct their work toward actual clinical needs, based on a wide variety of real-world data, rather than the limited supply of open datasets.
КАК ЭТО ОТЛИЧАЕТСЯ ОТ ДЕЦЕНТРАЛИЗОВАННЫХ ВЫЧИСЛЕНИЙ?
Федеративное обучение отличается от децентрализованных вычислений тем, что:
- Клиентские устройства (такие как смартфоны) имеют ограниченную пропускную способность сети. Они не могут передавать большие объемы данных, и скорость загрузки обычно ниже, чем скорость загрузки.
- Клиентские устройства не всегда доступны для участия в тренинге. Оптимальные условия, такие как состояние зарядки, подключение к неизмеренной сети Wi-Fi, бездействие и т. Д., Не всегда достижимы.
- Клиентские устройства могут отказаться от участия в тренинге.
- Количество доступных клиентских устройств очень велико, но несовместимо.
- Федеративное обучение включает в себя сохранение конфиденциальности с распределенным обучением и агрегацией среди большой части населения.
- Данные обычно несбалансированы, поскольку данные зависят от пользователя и являются самокоррелированными.
Федеративное обучение — это один из примеров более общего подхода «переноса кода в данные, а не данных в код», и он решает фундаментальные проблемы конфиденциальности, владения и местоположения данных.
В федеративном обучении:
- Определенные методы используются для сжатия обновлений модели.
- Качественные обновления выполняются, а не простые шаги градиента.
- Обновления градиентов обрезаются, если они слишком велики.
PySyft
PySyft библиотека с открытым исходным кодом, созданная для Федеративного обучения и сохранения конфиденциальности Это позволяет его пользователям выполнять частное и безопасное глубокое обучение. Он построен как расширение некоторых библиотек DL, таких как PyTorch, Keras и Tensorflow.
OpenMined / PySyftБиблиотека для зашифрованного, сохраняющего конфиденциальность глубокого обучения — OpenMined / PySyftgithub.com
Если вы более заинтересованы, вы также можете посмотреть на бумага опубликовано OpenMined о фреймворке.
В этой статье я покажу учебник, использующий расширение PySyft PyTorch.
Подготовка данных и отправка их удаленным работникам
Для моделирования удаленных данных мы будем использовать Набор сбора SMS-спама доступно на UCI Хранилище Машинного Обучения, Он состоит из ц. 5500 SMS-сообщений, из которых около 13% являются спам-сообщениями. Мы отправим примерно половину сообщений на устройство Боба, а другую половину — на устройство Анны.
Для этого проекта я выполнил некоторую предварительную обработку текста и данных, которую я не буду показывать здесь, но если вам интересно, вы можете взглянуть на скрипт Я использовал в наличии на моем GitHub стр. Также обратите внимание, что в реальной ситуации эта предварительная обработка будет выполняться на устройстве каждого пользователя.
Давайте загрузим обработанные данные:
Затем мы разделяем наборы данных на две части и отправляем их рабочим с классом.sy.BaseDataset:
При обучении в PyTorch мы используем DataLoaders для перебора пакетов. С PySyft мы можем сделать аналогичную итерацию с FederatedDataLoaders, где пакеты поступают с нескольких устройств федеративным способом.
How Federated Learning Works
AI algorithms deployed in medical scenarios ultimately need to reach clinical-grade accuracy. Largely speaking, this means that they meet, or exceed, the gold standard for the application to which they’re applied.
To be considered an expert in a particular medical field, you generally need to have clocked 15 years on the job. Such an expert has probably read around 15,000 cases in a year, which adds up to around 225,000 over their career.
When you consider rare diseases, which affect around one in 2,000 people, even an expert with three decades’ experience will have only seen roughly 100 cases of a particular condition.
To train models that meet the same grade as medical experts, the AI algorithms need to be fed a large number of cases. And these examples need to sufficiently represent the clinical environment in which they’ll be used.
But currently the largest open dataset contains 100,000 cases.
And it’s not only the amount of data that counts. It also needs to be very diverse and incorporate samples from patients of different genders, ages, demographics and environmental exposures.
Individual healthcare institutes may have archives containing hundreds of thousands of records and images, but these data sources are typically kept siloed. This is largely because health data is private and cannot be used without the necessary patient consent and ethical approval.
Federated learning decentralizes deep learning by removing the need to pool data into a single location. Instead, the model is trained in multiple iterations at different sites.
For example, say three hospitals decide to team up and build a model to help automatically analyze brain tumor images.
If they chose to work with a client-server federated approach, a centralized server would maintain the global deep neural network and each participating hospital would be given a copy to train on their own dataset.
Once the model had been trained locally for a couple of iterations, the participants would send their updated version of the model back to the centralized server and keep their dataset within their own secure infrastructure.
A centralized-server approach to federated learning.
If one of the hospitals decided it wanted to leave the training team, this would not halt the training of the model, as it’s not reliant on any specific data. Similarly, a new hospital could choose to join the initiative at any time.
This is just one of many approaches to federated learning. The common thread through all approaches is that every participant gains global knowledge from local data — everybody wins.
Federated learning still requires careful implementation to ensure that patient data is kept secure. But it has the potential to tackle some of the challenges faced by approaches that require the pooling of sensitive clinical data.
For federated learning, clinical data doesn’t need to be taken outside an institution’s own security measures. Every participant keeps control of its own clinical data.
As this makes it harder to extract sensitive patient information, federated learning opens up the possibility for teams to build larger, more diverse datasets for training their AI algorithms.
Implementing a federated learning approach also encourages different hospitals, healthcare institutions and research centers to collaborate on building a model that could benefit them all.
ГОМОМОРФНОЕ ШИФРОВАНИЕ
Гомоморфное шифрование — это форма шифрования, которая позволяет нам выполнять вычисления с зашифрованными операндами, что приводит к зашифрованному выводу. Этот зашифрованный вывод при расшифровке совпадает с результатом, полученным при выполнении тех же вычислений для фактических операндов.
Техника аддитивного разделения секрета уже обладает гомоморфным свойством. Если мы разделимИксвx1,x2,а такжеx3, а такжеYвy1,y2,а такжеy3, тогда,х + убудет равно значению, полученному после расшифровки суммирования трех акций: (x1 + y1), (х2 + у2) а также (x3 + y3).
Мы можем рассчитать значение агрегатной функции — сложение, не зная значенийИкса такжеY,
ССЫЛКИ
Переход федеративного обучения от концепции к производству не без проблем. Действительно, многое было достигнуто в отношении эффективности и точности федеративного обучения, тем более важные проблемы, на мой взгляд, связаны с безопасностью.
Ключевым фактором федеративного обучения является сохранение конфиденциальности, связанной с данными. Похоже, что даже когда фактические данные не предоставляются, повторные обновления веса модели можно использовать для выявления свойств, не глобальных для данных, а специфичных для отдельных участников.
Этот вывод может быть выполнен как на стороне сервера, так и на стороне клиента. Возможным решением будет использование методов «дифференциальной конфиденциальности» для снижения этого риска.
Обнаружение SMS-спама с помощью PySyft и PyTorch
Блокнот Jupyter с кодом ниже доступен на моей странице GitHub.
andrelmfarias / Private-AIРепозиторий с учебными пособиями и приложениями алгоритмов Private-AI с PySyft — andrelmfarias / Private-AIgithub.com
В этом уроке я буду моделировать двух рабочих, устройства Боба и Анны, где будут храниться SMS-сообщения. С PySyft мы можем моделировать эти удаленные машины, используя абстракциюVirtualWorkerобъект.
Сначала мы подключаем PyTorch:
import torchimport syft as syhook = sy.TorchHook(torch)
Затем мы создаемVirtualWorkers:
bob = sy.VirtualWorker(hook, id=»bob»)anne = sy.VirtualWorker(hook, id=»anne»)
Теперь мы можем отправить тензоры рабочим методомПошлите (рабочий) Например:
Вы, вероятно, получите что-то подобное в качестве вывода:
Вы также можете проверить, где находится тензор, на который указывает указатель:
Мы можем видеть, что тензор находится наVirtualWorkerназывается «Боб», и этот работник имеет один тензор.
Теперь вы можете выполнять удаленные операции, используя следующие указатели:
Вы можете видеть, что после операции мы получаем указатель в качестве возврата. Чтобы вернуть тензор, нужно использовать метод.получить()
sum = sum.get()print(sum)
Самое удивительное то, что мы можем выполнить все операции, предоставляемые PyTorch API для этих указателей, такие как вычисление потерь, возврат градиентов к нулю, обратное распространение и т. Д.
Теперь, когда вы понимаете основыVirtualWorkersа такжеуказателимы можем обучать нашу модель, используя федеративное обучение.
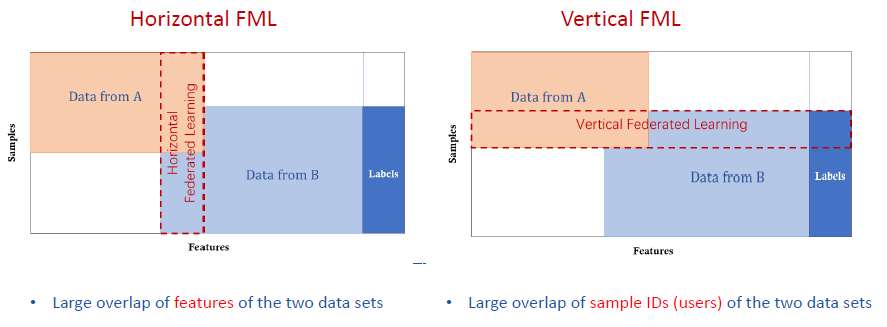
Вертикальное и горизонтальное федеративное обучение
Давайте возьмем пример двух банков из одной страны. Хотя у них непересекающаяся клиентура, их данные будут иметь схожие функциональные пространства, поскольку у них очень похожие бизнес-модели. Они могут объединиться для совместной работы на примере горизонтального федеративного обучения.

При вертикальном федеративном обучении две компании, предоставляющие различные услуги (например, банковское дело и электронная коммерция), но имеющие большое пересечение клиентуры, могут найти место для совместной работы в различных областях функций, которыми они владеют, что приведет к лучшим результатам для обеих сторон.

В обоих случаях владельцы данных могут сотрудничать, не раскрывая конфиденциальность своих клиентов, например, благодаря методам блокчейна. У них обоих будет доступ к большему количеству данных, чтобы лучше улучшить свои инициативы ИИ
В настоящее время федеративное обучение кажется идеальным для здравоохранения и банковской индустрии. Когда речь идет о банках, мы можем представить себе систему, в которой несколько банков могли бы обучать общей мощной модели обнаружения мошенничества, не делясь своими конфиденциальными данными клиентов друг с другом через федеративное обучение. Что касается больниц и других медицинских учреждений, они могли бы получить выгоду, если они согласятся предоставлять данные пациентов для модельного обучения с сохранением конфиденциальности.
Built by Healthcare for Healthcare
Large-scale federated learning projects are now starting, hoping to improve drug discovery and bring AI benefits to the point of care.
MELLODDY, a drug-discovery consortium based in the U.K., aims to demonstrate how federated learning techniques could give pharmaceutical partners the best of both worlds: the ability to leverage the world’s largest collaborative drug compound dataset for AI training without sacrificing data privacy.
King’s College London is hoping that its work with federated learning, as part of its London Medical Imaging and Artificial Intelligence Centre for Value-Based Healthcare project, could lead to breakthroughs in classifying stroke and neurological impairments, determining the underlying causes of cancers, and recommending the best treatment for patients.
Discover more about federated learning and explore the topic further on the NVIDIA Technical Blog. Learn about the science behind the approach in this paper.
Обучение модели ГРУ
Для этой задачи я решил использовать классификатор на основе одноуровневой сети GRU. К сожалению, текущая версия PySyft пока не поддерживает модули RNNs PyTorch. Однако мне удалось создать простую сеть GRU с линейными слоями, которые поддерживаются PySyft.
Поскольку в центре нашего внимания находится использование инфраструктуры PySyft, я пропущу построение модели. Если вы заинтересованы в том, как я его построил, вы можете проверить это скрипт на моем GitHub стр.
Давайте начнем модель!
from handcrafted_GRU import GRU# Training paramsEPOCHS = 15CLIP = 5 # gradient clipping — to avoid gradient explosion lr = 0.1BATCH_SIZE = 32# Model paramsEMBEDDING_DIM = 50HIDDEN_DIM = 10DROPOUT = 0.2# Initiating the modelmodel = GRU(vocab_size=VOCAB_SIZE, hidden_dim=HIDDEN_DIM, embedding_dim=EMBEDDING_DIM, dropout=DROPOUT)
А теперь тренируйся!
Обратите внимание на строки 8, 12, 13 и 27. Это шаги, которые отличают централизованное обучение в PyTorch от федеративного обучения с PySyft.
После возвращения модели в конце цикла обучения мы можем использовать ее для оценки ее производительности на локальных или удаленных тестовых наборах с помощью аналогичного подхода. В этом случае мне удалось достичь более 97,5% Оценка AUC, показывая, что обучение моделей в федеративном порядке не влияет на производительность. Тем не менее, мы можем заметить увеличение общего времени вычислений.
Вывод
Мы можем видеть, что с библиотекой PySyft и ее расширением PyTorch мы можем выполнять операции с тензорными указателями, как мы можем делать с PyTorch API (но для некоторых ограничений, которые еще предстоит устранить).
Благодаря этому мы смогли обучить модель детектора спама, не имея доступа к удаленным и частным данным: для каждой партии мы отправляли модель текущему удаленному работнику и возвращали ее на локальный компьютер, а затем отправляли на рабочий следующей партии.
Однако у этого метода есть одно ограничение: возвращая модель, мы все равно можем получить доступ к некоторой частной информации. Допустим, у Боба было только одно SMS на его машине. Когда мы вернем модель, мы можем просто проверить, какие вложения модели изменились, и мы узнаем, какие были токены (слова) SMS.
Для решения этой проблемы существует два решения: дифференциальная конфиденциальность и защищенные многопартийные вычисления (SMPC). Дифференциальная конфиденциальность будет использоваться, чтобы убедиться, что модель не предоставляет доступ к некоторой частной информации. SMPC, который является одним из видов шифрованных вычислений, в свою очередь, позволяет вам отправлять модель конфиденциально, чтобы удаленные работники, у которых есть данные, не могли видеть веса, которые вы используете.
Я покажу, как мы выполняем эти методы с PySyft в следующей статье.
Не стесняйтесь оставлять отзывы и задавать вопросы!
Если вы заинтересованы в получении дополнительной информации о безопасном и частном ИИ и о том, как использовать PySyft, вы также можете проверить это бесплатный курс по Udacity, Это отличный курс для начинающих, который преподает Эндрю Траск, основатель инициативы OpenMined.
Теперь мы реализуем федеративный подход к обучению для обучения простой нейронной сети в наборе данных MNIST, используя двух рабочих: Джейка и Джона. Существует только несколько модификаций, необходимых для применения подхода федеративного обучения.
2. Загрузите набор данных.
В реальных приложениях данные присутствуют на клиентских устройствах. Чтобы повторить сценарий, мы отправляем данные в VirtualWorkers.
Обратите внимание, что мы создали обучающий набор данных по-другому.train_set.federate ((Джейк, Джон))создаетFederatedDatasetгдеtrain_setразделен между Джейком и Джоном (два наших VirtualWorkers) FederatedDatasetкласс предназначен для использования как PyTorch’sDatasetучебный класс. Передать созданноеFederatedDatasetфедеративному загрузчику данныхFederatedDataLoaderИтерировать по-федеративно. Затем партии поступают с разных устройств.
3. Построить модель
4. Тренируй модель
Поскольку данные присутствуют на клиентском устройстве, мы получаем их местоположение черезместо расположенияатрибут. Важными дополнениями к коду являются шаги по возвращению улучшенной модели и стоимости потерь от клиентских устройств.
5. Протестируйте модель
Test set: Average loss: 0.2428, Accuracy: 9300/10000 (93%)
Это оно. Мы подготовили модель с использованием подхода федеративного обучения. По сравнению с традиционным обучением обучение модели с использованием федеративного подхода занимает больше времени.
СТРАТЕГИЯ
Мы можем выполнить федеративное обучение на клиентских устройствах, выполнив следующие действия:
- проводить обычные тренировки, используя данные, представленные на устройстве,
- вернись умнее модель.
Однако, если кто-то перехватывает более разумную модель, пока она используется совместно с сервером, он может выполнитьразобрать механизм с целью понять, как это работаети извлекать конфиденциальные данные о наборе данных. Методы дифференциальной конфиденциальности решают эту проблему и защищают данные.
Когда обновления отправляются обратно на сервер, сервер не должен быть в состоянии различать при агрегировании градиентов. Давайте использовать форму криптографии, называемую аддитивным секретным обменом.
Мы хотим зашифровать эти градиенты (или обновления модели) перед выполнением агрегирования, чтобы никто не смог увидеть градиенты. Мы можем достичь этого путем дополнительного секретного обмена.
Федеративное обучение позволяет легче, безопаснее и дешевле применять машинное обучение в регулируемых и конкурентоспособных отраслях. С помощью FL компании могут улучшать свои модели и улучшать свои приложения ИИ.В области медицины FL может быть синонимом лучшего лечения и более быстрого открытия лекарств.
Вскоре я ожидаю увидеть больше альянсов промышленных данных на многих вертикальных рынках, например, финансовая индустрия может сформировать альянс финансовых данных, а медицинская индустрия может сформировать альянс медицинских данных. В долгосрочной перспективе мы также можем ожидать объединения данных между компаниями из разных отраслей, но с одним и тем же видением ИИ.
Если вы заинтересованы в получении более технических деталей, я рекомендую это Веб-сайт ,



